
Comment gérer, optimiser et exploiter, dans une perspective FinOps, un cluster Kubernetes hébergé dans un environnement Cloud.
Dans le monde de Kubernetes et surtout avec les services managés, l'allocation des coûts peut être un véritable cauchemar car pour obtenir une bonne précision, il faut considérer et identifier de multiples ressources.
Pour résumer rapidement un parcours FinOps, vous avez trois phases :
- Informer (savoir où vous avez dépensé vos $$$, c'est-à-dire visibilité/allocation des coûts).
- Optimiser (optimisation des coûts à l'aide de la réduction des taux/stratégie de réduction d'échelle/...)
- Opérer (amélioration et suivi continus de votre stratégie FinOps. L'automatisation fait également partie de cette phase)
Pour chaque phase, nous allons essayer de décrire les concepts clés et la meilleure approche, en fonction du fournisseur de Cloud (principalement Amazon Web Services et Microsoft Azure) et de l'environnement du Cluster (production/non-production).
Informer
Dans le monde de Kubernetes et surtout avec les services managés, l'allocation des coûts peut être un véritable cauchemar car pour obtenir une bonne précision, il faut considérer et identifier de multiples ressources. Des ressources au niveau de Kubernetes comme les pods mais aussi au niveau du fournisseur de Cloud car vous devez prendre en compte des coûts comme l'équilibreur de charge/le nœud/le stockage/le réseau/....
La répartition des coûts est le processus qui consiste à diviser vos factures et à associer chaque partie à un centre de coûts, qui peut être une application/un service/une équipe/et à essayer d'obtenir la plus grande précision. En procédant ainsi, vous gagnez en visibilité sur les coûts. Dans un environnement cloud, ce n'est pas facile car certaines ressources sont partagées entre de nombreux centres de coûts. Vous devez également gérer les remises comme la réservation, la bande passante du réseau, et bien d'autres éléments.
Pour l'obtenir, des tags sont utilisés pour identifier le propriétaire des ressources (ex : application1), puis une stratégie supplémentaire doit être établie pour allouer les éléments non tagués/non taggables.
De plus, les fournisseurs de cloud computing facturent au niveau de l'hôte (à l'exception d'AWS EKS fonctionnant en mode Fargate complet et GKE Autopilot), et non au niveau du conteneur. Vous devez donc allouer une quantité donnée de ressources de l'hôte (vCPU/Mémoire/...) à chaque conteneur, puis la résumer en suivant votre stratégie d'application des tags. Vous devez également tenir compte des "coûts partagés", comme le coût principal de Kubernetes, et des "coûts d'inactivité" (pourcentage de ressources hôte inutilisées). Vous ne pouvez pas utiliser le service de gestion des coûts d'un fournisseur de cloud commun comme AWS Cost Explorer ou Azure Cost Management pour créer la distribution des coûts.
L'utilisation d'un outil tiers comme Cloudhealth pourrait être vraiment utile dans votre tâche de répartition des coûts, mais elle a un coût élevé. À moins que vous ne puissiez utiliser des outils comme Kubecost pour obtenir une estimation de la répartition des coûts (fonctionne avec AWS et GCP).
Il n'y a pas de stratégie universelle qui fonctionne dans tous les cas, vous devez trouver la plus adaptée à votre cas d'utilisation. Mais nous pouvons essayer de donner quelques lignes directrices :
Optimiser
La phase d'optimisation se concentre sur les processus de réduction des coûts. Certains d'entre eux peuvent être mis en œuvre sans tenir compte du fournisseur de cloud, mais d'autres dépendent de ses spécifications.
Nous pouvons regrouper les optimisations en quatre catégories :
En guise d'aide rapide, consultez le schéma ci-dessous pour trouver l'ordre des optimisations recommandées en fonction de l'environnement du cluster (production ou non-production) :
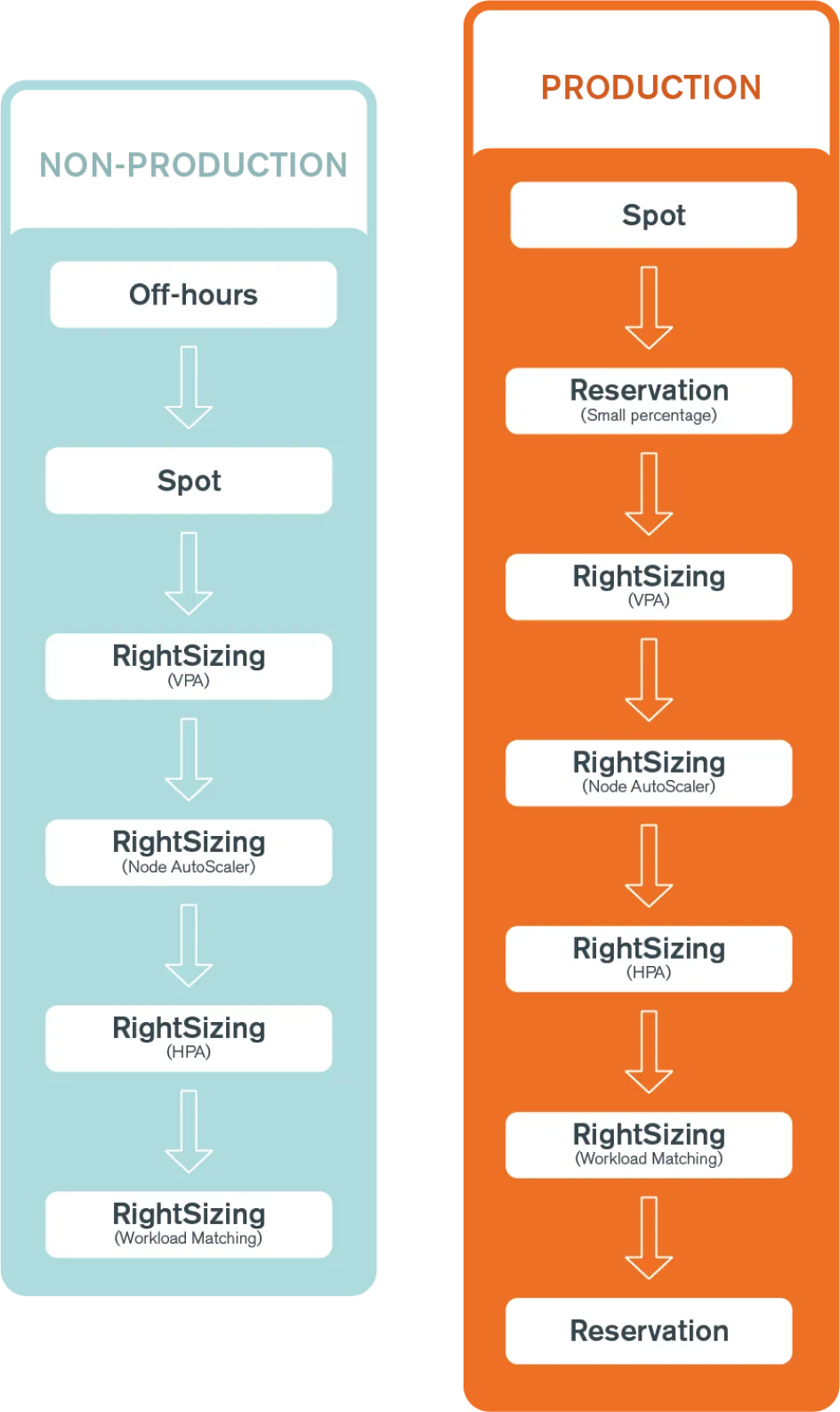
Redimensionnement
Le redimensionnement peut être effectué au niveau du pod/conteneur et/ou au niveau de l'hôte/nœud.
Remarque : le redimensionnement signifie l'ajustement des capacités des ressources, mais aussi l'ajout/le retrait de ressources identiques.
Conteneur
Dans le monde des conteneurs, il existe plusieurs stratégies de scaling : le scaling horizontal, le scaling vertical et le scaling des nœuds.
Scaling horizontal (HPA)
À l'instar d'un groupe EC2 AutoScaling ou d'un Azure VMSS, le scaling horizontal vise à ajouter ou supprimer des ressources (pod dans ce cas) pour suivre la charge de travail actuelle.
L'autoscaler de pods horizontaux de Kubernetes est conçu pour les applications stateless, qui peuvent démarrer rapidement pour gérer les pics d'utilisation et s'arrêter de manière élégante.
Scaling vertical (VPA)
Contrairement au scaling horizontal, qui ajoute ou supprime des pods, le scaling vertical (peut) augmenter ou diminuer les ressources des pods (CPU/Mémoire) après une période d'évaluation.
L'autoscaler vertical de Kubernetes est particulièrement utile pour ajuster les demandes de CPU et de mémoire à la consommation réelle des conteneurs. Souvent, les demandes des conteneurs sont surdimensionnées, ce qui entraîne un gaspillage de ressources.
VPA peut ajuster automatiquement les ressources des conteneurs mais ce n'est pas recommandé, utilisez-le comme une recommandation et ajustez ensuite vos définitions de ressources Kubernetes.
OUTIL : Consultez le rapport open-source kube-resource-report pour obtenir un rapport VPA en HTML.
Redimensionnement des nœuds
Vos pods utilisent des ressources des nœuds, donc lorsque vous utilisez HPA ou VPA, il est obligatoire de pouvoir ajuster leur capacité.
Le Kubernetes Cluster Autoscaler peut ajouter ou supprimer des nœuds pour optimiser la capacité des ressources du cluster.
Le PodDistruptionBudget est un élément indispensable lorsque le cluster Autoscaler est activé pour éviter les temps d'arrêt des applications.
Un autre concept important, concernant le scaling des nœuds, est la cohérence avec la charge de travail.
L'adaptation de la charge de travail signifie que vous devez prendre en compte le ratio CPU/mémoire de votre nœud pour éviter d'avoir trop de mémoire ou de CPU inutilisés.
Par exemple, vos pods consomment plus de mémoire que de CPU, mais la capacité des nœuds est plus ou moins égale. Dans ce cas, vous allez gaspiller des ressources CPU et augmenter le coût de votre infrastructure.
Pour éviter cela, changez le type d'instance de nœud pour obtenir une instance optimisée pour la mémoire.
Pour détecter le problème de cohérence avec la charge de travail, vérifiez l'"utilisation demandée du CPU" et l'"utilisation demandée de la mémoire". Vous devriez avoir quelque chose de similaire. Par exemple, vous avez un problème si votre "utilisation du CPU" est de 100% alors que la "demande de mémoire" n'est que de 50%.
Heures creuses
Off-hour signifie arrêter ou réduire la capacité des ressources la nuit (et les week-ends). Pour les environnements de non-production, cela devrait être une norme !
Un arrêt des ressources entre 20h00 et 07h00 et pendant le week-end réduit son prix de 60%. Mieux qu'une réservation !
kube-downscaler est le point d'entrée pour les clusters de production et de non-production (doit être combiné avec le Cluster Autoscaler pour faire des économies).
Ce projet open-source réduira les déploiements/ensembles statiques/HPA en fonction des politiques définies (heure/non conforme aux conditions d'exclusion comme la restriction des namespaces).
Production
Dans un environnement de production, vous devez veiller à ce que, même en dehors des heures de travail, votre cluster/application client reste hautement disponible et tolérant aux pannes :
- ayant au moins 2 réplicas de chaque application critique
- répartis sur au moins 2 nœuds
Il ne s'agit pas vraiment d'heures creuses, mais plutôt d'une réduction d'échelle lorsque la charge du cluster diminue.
Non-production
Un cluster non productif devrait pouvoir être réduit à 0 worker, mais avec les clusters Kubernetes managés, certains services de cloud computing ont des limitations (voir ci-dessous).
cluster-turndown est un projet open-source permettant d'effectuer facilement les opérations hors production. Actuellement, le projet supporte GKE, EKS et KOPS sur AWS.
AWS EKS
Vous pouvez réduire le nombre de workers (groupe géré ou non géré) à 0, mais n'oubliez pas qu'AWS facture toujours la gestion du cluster (0,10$/heure).
AZURE AKS
Azure AKS est différent d'AWS car Azure ne facture pas la gestion du cluster (sauf si vous ajoutez l'option uptime SLA mais cette option n'a pas de sens pour un cluster de non-production) mais vous ne pouvez pas réduire le pool de nœuds par défaut (système) à 0.
Donc... vous avez un coût constant. Le coût dépend de la taille de la machine virtuelle. Pour les pools de workers, vous pouvez les réduire à 0.
Spot Node
Les Spot Nodes sont un autre bon moyen de réduire le coût des clusters Kubernetes. D'une manière générale, les instances/machines virtuelles ponctuelles sont des ressources "normales" bénéficiant d'un rabais important. Mais ce rabais a un inconvénient, les fournisseurs de cloud ne garantissent pas la disponibilité des ressources. Elles peuvent être interrompues à tout moment.
Cela signifie que les applications en cours d'exécution doivent être tolérantes aux pannes pour un environnement de production (en dehors de la production, ce n'est pas obligatoire mais vous/le client devez accepter le risque d'avoir un temps d'arrêt jusqu'à ce qu'un nouveau nœud soit prêt).
Chaque fournisseur de cloud propose un moyen de recevoir une notification (API de métadonnées locales) quelques secondes/minutes avant l'arrêt du nœud. Cela permet d'atténuer l'impact de l'extinction du nœud.
Pour une utilisation réussie des nœuds Spot, vous devriez envisager d'utiliser :
- l'affinité et l'anti-affinité des nœuds (identifier les pods qui peuvent supporter/être déployés sur les nœuds Spot).
- le cluster-autoscaler Kubernetes avec :
- la fonctionnalité cluster-autoscaler expander (pour se replier automatiquement sur le type à la demande s'il n'y a plus de spot disponible).
- la fonction MixedInstancePolicy de cluster-autoscaler (prend différentes instances (doivent avoir la même capacité CPU & Mémoire) pour améliorer la disponibilité des Spots. Exr5.2xlarge/r5a.2xlarge/r5d.2xlarge/r5ad.2xlarge/i3.2xlarge) - Seulement pour AWS
AWS a annoncé en décembre 2020 la prise en charge des instances spot dans un groupe de nœuds managés. Avec cette nouvelle fonctionnalité, le drain des nodes et la stratégie des spots sont gérés par AWS.
En outre, elle offre une stratégie d'allocation optimisée en fonction de la capacité et un rééquilibrage de la capacité, deux fonctionnalités intéressantes pour les groupes Spot AutoScaling.
Azure a quelques limitations/conditions pour pouvoir utiliser les nœuds Spot :
Le pool de nœuds par défaut (système) ne supporte pas le nœud spot (et doit avoir au moins 1 VM).
Vous ne pouvez pas mélanger des nœuds standard et spot dans le même pool de nœuds. Vous devez créer un (ou plusieurs) pool de nœuds standard et un autre (ou plusieurs) pool de nœuds spot.
Production
Le conseil le plus courant pour utiliser les nœuds spot dans un cluster de production est de répartir la capacité des nœuds entre les nœuds à la demande/standard et les nœuds spot afin d'éviter de subir un arrêt complet en cas de non disponibilité des nœuds spot. La distribution dépend principalement des applications hébergées.
Par exemple, la distribution pourrait être :
- 30% Spot - 70% On-Demand/Standard
- 50% Spot - 50% On-Demand/Standard
- 70% Spot - 30% On-Demand/Standard
Hors production
Dans un environnement de non-production, votre stratégie ponctuelle peut être beaucoup plus agressive qu'en production car il n'y a pas de besoin de disponibilité absolue. Vous pouvez même cibler la distribution avec uniquement des nœuds spot. Sinon, comme pour un environnement de production, choisissez un équilibre entre On-Demand/Standard et spot.
Réservation d'Instance/VM
AWS : avant de lire la section suivante, vous devez comprendre le concept et les différences entre Instance Reservations et Saving Plans.
Production
Pour un cluster de production, et en général, vous devriez commencer dès que possible le processus de réservation. Vous pouvez commencer lentement en réservant seulement, par exemple, 10 % de votre capacité et réserver davantage au fil du temps.
AWS
Dans le cas de l'utilisation d'AWS Fargate (partielle ou totale), c'est un choix facile car seuls les Compute Saving Plans peuvent couvrir à la fois EC2 et Fargate.
Sinon, si vous avez un mélange d'instance On-Demand et Spot, vous pouvez choisir de couvrir 100% de votre On-Demand et si vous n'avez pas d'instance Spot, cela dépend de la charge du cluster. Pour les deux, veuillez consulter cette page pour savoir comment choisir la bonne option.
Azure
Le point de départ est d'acheter des machines virtuelles réservées pour le pool de nœuds par défaut (système). Ensuite, si vous avez un mélange d'instance Standard et Spot, vous pouvez choisir de couvrir 100% de votre instance Standard et si vous n'avez pas d'instance Spot, cela dépend de la charge du cluster.
Avec la fonction d'annulation de réservation, vous pouvez être vraiment agressif sur la couverture des réservations, car le seuil de rentabilité est rapidement atteint (les frais d'annulation ne représentent que 3 % des frais de réservation restants). Consultez la documentation Azure pour plus d'informations.
Non-production
AWS
Si vous ne faites pas tourner votre cluster avec uniquement des nœuds Spot et ne passez pas à des pools de 0 nœud pendant les nuits/week-ends, vous pouvez réserver le nombre de nœuds de fonctionnement minimum.
Azure
Comme vous ne pouvez pas réduire le pool de nœuds par défaut (système) à 0, vous pouvez acheter des machines virtuelles réservées pour les couvrir.
Pour les pools de worker nodes, si vous réduisez à 0 pendant les nuits/week-ends, vous ne pouvez pas acheter de réservations. Sinon, vous pourriez réserver le nombre de nœuds en fonctionnement minimum.
Grâce à la fonction d'annulation des réservations, vous pouvez être très agressif sur la couverture des réservations, car le seuil de rentabilité est rapidement atteint (les frais d'annulation ne représentent que 3 % des frais de réservation restants). Consultez la documentation Azure pour plus d'informations.
Spécificités de AWS Fargate
Obligatoire :
- charges de travail interruptibles uniquement
Limitations :
- statefulset non pris en charge (utiliser EFS pour le volume persistant)
- pas disponible dans toutes les régions AWS
- ne prend en charge que ALB comme type d'équilibreur de charge
- max 4vCPU et 30GB de mémoire par conteneur
Options :
- Fargate
- Fargate avec des instances ponctuelles
Modèle de tarification :
- Par vCPU par heure et par mémoire (GB) par heure.
Fargate est un bon candidat pour :
- très petit cluster
- test rapide/POC
Opération
La phase d'exploitation permet d'améliorer continuellement votre stratégie FinOps. Ses contrôles permettent de réaliser :
- Évolution du coût global
- Évolution des coûts élément par élément
- Donner aux développeurs les moyens de suivre leur utilisation de Kubernetes et les inciter à le faire.
- Utiliser la dernière fonctionnalité du fournisseur Cloud (ex : disponibilité de la nouvelle génération d'instance/vm)
- Vérifier si de nouvelles optimisations peuvent être appliquées
Il s'agit d'une liste non exhaustive de choses à faire/vérifier pendant la phase d'exploitation, qui DOIVENT être effectuées sur des environnements de production ET de non-production.
Ressources
Vous trouverez ci-dessous une liste de ressources utiles liées à Kubernetes dans une perspective FinOps :
Google Cloud Best Practices for running cost effective Kubernetes (en anglais)
Livre blanc FinOps for Kubernetes de la FinOps Foundation (en anglais)
L'article original est disponible en anglais sur Medium.