Continuous Delivery Pipeline: Wie Deployment-Workflows optimal automatisiert werden

Michael Riexinger
Head of Cloud Infrastructure Engineering
Aufgrund der bestehenden Komplexität von Container Virtualisierung ist es sinnvoll, eine Continuous Delivery Pipeline zu etablieren, mit der neuer Code, Bugfixes oder neue Versionen von 3rd-Party-Software eingespielt werden kann. Da in diesem Umfeld nichts mehr in die laufende Umgebung deployt wird (Immutable Infrastructure), ändert sich auch der gewohnte Weg von solchen Pipelines. Generell bietet es sich an, ein Git-Repository als Code-Repository zu haben und ein separates für die Pflege des/der Docker-Images. Als Job-Scheduler kann beispielsweise Gitlab-CI oder Jenkins genutzt werden. Letzteres bietet sich an, da es hierfür unzählige Plugins, beispielsweise für Docker oder auch Kubernetes gibt und Jenkins sehr flexibel ist.
Continuous Delivery am Beispiel von Spryker und Kubernetes
In folgender Zeichnung findet sich ein exemplarischer Deployment-Workflow für das E-Commerce-Framework Spryker im Zusammenspiel mit Kubernetes. Der Entwickler pusht in diesem Fall den Code in ein gemeinsames Code-Repository und gibt an, in welche Umgebung (Live, Stage oder Dev) er deployen möchte. Daraufhin läuft ein Jenkins-Job, welcher dieses Repository auscheckt, die Images mit dem neuen Code baut, testet und in der Image-Registry published. Daraufhin wird Kubernetes angewiesen, diese Images aus der Registry zu ziehen und die Pods neu auszurollen.
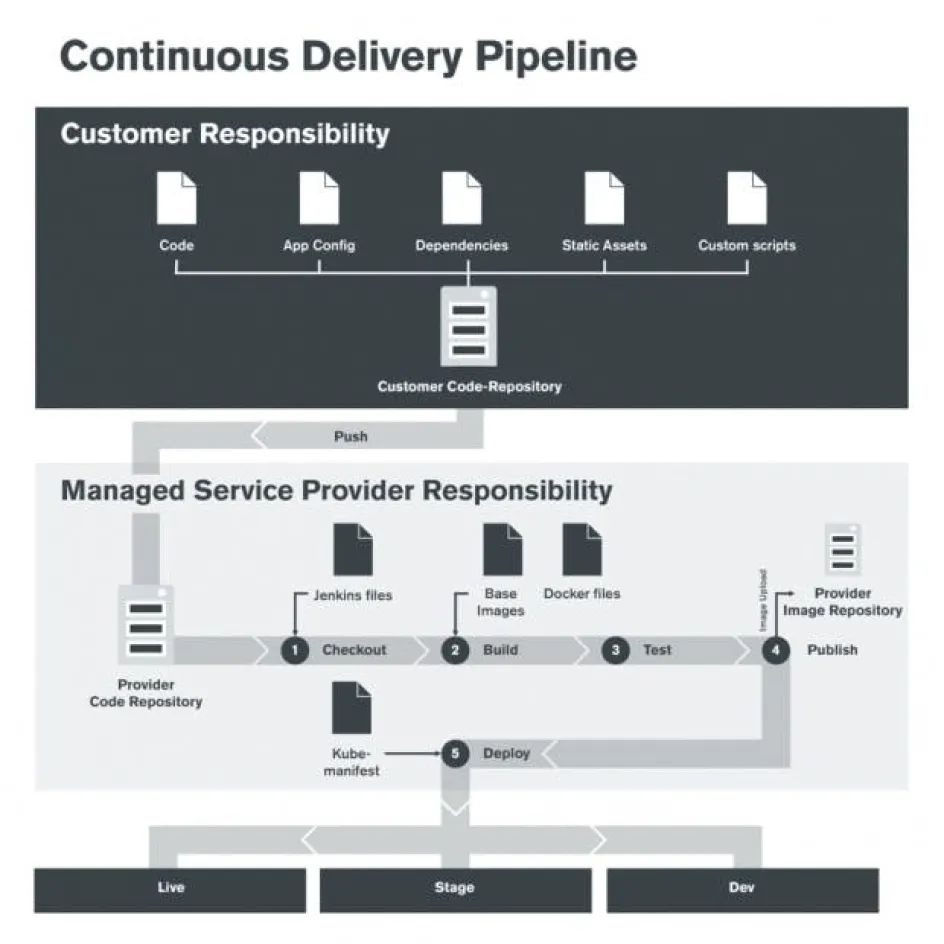
Caveats – was du beachten solltest
Damit dies alles reibungslos funktioniert, ist Folgendes unbedingt zu berücksichtigen: Beim Containerdesign sollte darauf geachtet werden, den Container als statische „Black-Box“ zu sehen. Ideal ist, wenn nur ein Prozess beziehungsweise Service pro Container läuft. Hier gibt es sicherlich Ausnahmen, wie PHP, bei denen es sinnvoll sein kann, nginx und php-fpm im selben Container zu haben. Das Container-Image sollte idealerweise sinnvolle „defaults“ in den Konfigurationsdaten mitbringen, die jedoch von extern durch Variablen überschrieben werden können. Dies macht das Image deutlich universaler. Nutzdaten dürfen niemals in Containern gespeichert werden. Zum einen gehen diese nach einem Neu-Deployment verloren, zum anderen ist die Performance deutlich schlechter. Für Nutzdaten muss daher ein externes, persistentes Volume genutzt werden. Auf Shared Storage zwischen Containern sollte grundsätzlich verzichtet werden. Wenn dies nicht möglich ist, sollte idealerweise nicht NFS, sondern ein Object-Store wie S3 verwendet werden.
Im Kubernetes-Kontext bietet es sich an, einen Paketmanager wie Helm zu nutzen, um die mangelnde Parametrisierbarkeit von Kubernetes-Manifesten zu umgehen. Wenn Scaling/Auto-Scaling verwendet wird, muss vorher sichergestellt werden, dass die Cloud, in welcher der Kubernetes-Cluster läuft, eine Integration in Kubernetes hat. Wenn nicht, muss diese selbst geschaffen werden. Generell muss der „Everything-as-Code“-Gedanke unbedingt gelebt werden. Wer hier noch wenig Erfahrung hat, sollte sich folgende Tools genauer ansehen:
- Cloud: Terraform
- Cluster: Kubernetes-Manifests, Helm
- Jenkins: Job-DSL-Plugin, continuous delivery Pipeline-Plugin
- Dynamische Orchestrierung/Konfigurationsmanagement: Ansible
- Für alles andere: Shellscripts, Python, Perl
Mit den genannten Tools in petto und der Berücksichtigung einiger Dos and Don’ts erhält man eine sehr moderne, dynamische und hochskalierende Umgebung. Änderungen sind Entwicklern und Operations komplett transparent und können jederzeit reproduziert werden. Alle Umgebungen sind durchweg konsistent, sodass auf Integrationstests Verlass ist: eine optimale continuous delivery pipeline.
Lesen Sie auch den ersten Teil dieser Artikelserie: Container-Virtualisierung: Docker und Kubernetes erfolgreich einsetzen