
Which home for your data?
The terms “Database”, "Data Warehouse” and “Data Lake” are often used interchangeably, but what are they and what are their differences?
In this blog, Andrew Curry, Principle Analyst, attempts to explain what each has in common and what differs between each and when to use each of them.
Whether you are aware of it or not, databases are a part of everyone’s daily routine. Even people who don’t own a computer or mobile phone interact with some sort of database regularly. When you withdraw money from a cash machine, view your Facebook or Twitter accounts, or perform almost any interaction digitally you will be accessing some kind of database.
During lockdown, I, like many of us, have been doing more DIY and the tools I use are stored in toolboxes in the garage. Paraphrasing Lee Easton (president of data-as-a-service provider aerovision) if you consider the tools to be data then this becomes a good analogy of a database, data warehouse, and data lake.
- The tools organised in the toolboxes are stored in a specific, accessible, and organised way, this is your database
- The garage where all this is stored is the data warehouse. You might have lots of toolboxes in the garage. Some toolboxes might be yours, but you could store the toolboxes of your family/friends or neighbours until you reach the capacity of your garage. Though you’re storing their tools, their owners still keep them organised in their toolboxes.
- If everyone just dumped the tools, there is probably a mixture of organised and unorganised tools —this is your data lake. In a data lake, the data is a mixture of raw, unorganized, and in many cases unstructured, structured, and something in between data.
“If you don’t know where you are going, any road will take you there”
George Harrison
It's a common misconception that designing and implementing a database or data store of any kind is easy to do and could be done by any system admin. The reality is that this is simply not the case. A business's requirements must be properly identified, they must be translated into a suitable design and implemented with the business needs at the forefront, and then tested thoroughly. Should this not be done then you will be trying to constantly retrofit changes which could not only prove expensive but also may not be possible without large refactoring.
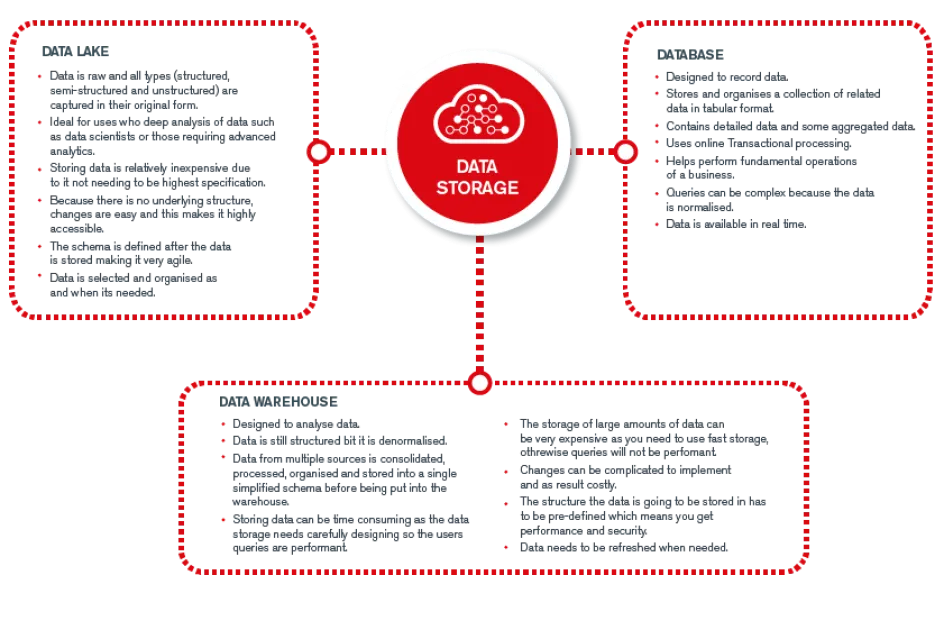
Databases
A database is a storage location that houses structured data.
Now to complicate this a little - you have 2 main types of databases; Relational and NoSQL.
NoSQL is a bit of a lazy term, in reality, these are just new technologies with completely different ideas to SQL databases.
If you take a typical work location, you will find you probably have information stored in many different ways:
- Some stored in a file system or a cabinet
- Some are dumped randomly on your desk in the form of document printouts, post-it notes, etc...
- Some pinned to a board
Why do we do this? Because each kind of data has different properties and you need it for different purposes.
Your board is full of the data and you need quick access too (think a memory database like Memcached which is NoSql).
- Your cabinet is full of data which you may rarely look at but it will be very important in the future. (Relational)
- Your desk is full of the data you currently need quick access to, it's probably in many formats and there is probably no real order because if you ordered it would slow you down (document storage, i.e. NoSQL)
Just like you choose different storage methods for the different data on your desk, we use different storage methods for each kind of information on a computer system.
A relational database uses a structured query language (SQL). This is used for defining and manipulating data. SQL is very powerful, versatile, and widely used. This makes it an excellent choice and very good for complex analysis and structures that don’t change much once they have been defined.
SQL can though be restrictive, it requires that you determine the structure of your data before you can even look at working with it. This requires significant upfront work and any changes in structure can be quite disruptive to your whole system.
NoSQL databases in contrast have dynamic schemas and store unstructured data. The data is stored in many different formats from column orientated to key-value. This flexibility means that in these systems you can create documents without first having to define their structure, syntax can be different between databases and you can also alter things without impacting everything else in the system.
Relational databases tend to be vertically scalable, which means you can increase the load a server can take by increasing things like CPU, Memory, Disk speed. NoSQL databases on the other hand are horizontally scalable. That means you can increase your load by splitting them across more servers (sharding). Think of it as adding more floors to the same building versus adding more buildings to a neighbourhood. The problem is physics says you can only build so high, whereas you can build horizontally over a larger scale.
Relational databases we are currently supporting are:
- Oracle
- Informix
- SQL Server
- Postgres
- Mysql
- Maria DB
- Db2
The NoSql databases we have experience in are:
- MongoDB
- Cassandra
- Redis
- Oracle NoSQL
- Amazon DynamoDB
- Couchbase
- Memcached
- CouchDB
- Influxdb
Many of the larger Relational databases now also support NoSQL.
Data Warehouses
While a database stores real-time information about one particular part of your business, a data warehouse on the other hand pulls together data from many different sources for reporting and analysis.
Data Warehouses via complex reporting and analysis tend to be used to:
- Manage the risks of the business
- Evaluate organisational risks
- Identify new business opportunities
Many of the same database flavours are used for data warehousing. The main difference is in how they are being used. Data warehouses generally keep well-known and structured data. They provide support for pre-created and dynamic reports that are scaled across many business users.
Databases use OnLine Transactional Processing (OLTP) to delete, insert, and update large numbers of online transactions quickly. This type of processing immediately responds to user requests, and so is used to process the real-time operations of a business. For example, placing a bet or buying something from Amazon.
Data warehouses use OnLine Analytical Processing (OLAP) to analyse massive volumes of data rapidly. This process gives analysts the ability to look at your data from different perspectives. For example, even though your database records data for every second of every day, you may just want to know the total amount each day. OLAP is specifically designed to do this. In the real world, many systems are a hybrid of OLTP and OLAP systems.
Claranet looks after many large systems, one of these ‘spaces’ is for betting and gaming where thousands of transactions are processed every second, and response times of 0.001 of a second, are flagged as slow. However, these same systems will run very large data warehouse-type queries often using the same data sets.
Claranet is familiar with a large range of ETL (Extract Transform Load) tools for helping with data transforms.
Data Lakes - Pools, streams, and Swamps
Where a database and data warehouse are full of pre-defined structured data, a Data Lake is the complete opposite. A data lake is an extensive ‘pool’ of unprocessed data where at least at the beginning its purpose is undefined. As the name suggests it is similar to a real lake where you have multiple streams coming in and out, a data lake has structured data and unstructured data flowing through in real-time.
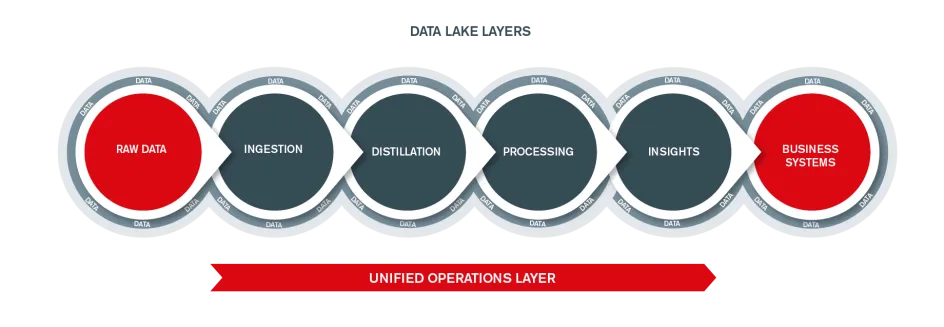
Whilst words like structured and unstructured data are banded around, data lakes are not a dumping ground. If you are not very careful, your data lake will be a ‘data swamp’ which, as the name suggests, is not useful to anyone.
The best definition of a data swamp I have found is, “An unstructured, ungoverned, and out of control Data Lake where due to a lack of process, standards, and governance, data is hard to find, hard to use, and is consumed out of context.” Source: https://www.nvisia.com/insights/data-swamp Nate Feldmann
Whilst there is a lot out there on what a data lake is or isn't, the common misconception that there is no real analysis stage is wrong. You still need to ask yourself important questions such as:
- What is the purpose of my Data Lake?
- What sort of analytics am I wanting to use it for?
- What data sources do I need in there?
- How long am I keeping my data?
- How will I tag my data?
“Without descriptive metadata and a mechanism to maintain it, the data lake risks turning into a data swamp. And without metadata, every subsequent use of data means analysts start from scratch.” Gartner’s “Beware the Data Lake Fallacy.
Without metadata around the data, you do not know the context, its format, its structure, etc. You need to know what your data is otherwise you are bound to waste time over and over again reanalysing the data each time.
Whilst at Claranet we don't currently manage any Data Lakes, we do look after a lot of the technology that are their building blocks.
How do they compare?
| TYPE | DATABASE | DATA WAREHOUSE | DATA LAKE |
|---|---|---|---|
| Data Type Support | Defined and structured data | Defined, structured, and processed data | Structured, semi-structured, and unstructured data |
| User Support | Operational users | Operational users, data analysts | Operational users, data analysts, and data scientists |
| Schema Design | Fixed definition/Relational | Fixed definition/Relational | No Schema |
| Flexibility | Low | Medium | High |
| Primary use | Transactional | Analytics and reporting | Analytics |
| Development | Top-down | Top-down | Bottom-up |
| Purpose | Pre-determined | Pre-determined | Unknown |
| Cost | Low | Medium | High |
| Design time | Medium | High | Low |
What should a business choose?
If you only run your business on a handful of databases you are probably fine running your transactions and reporting on the same system. If you have many databases and structured sources but no data warehouse or data lake then it's well worth looking if your business could benefit from either of these systems.
If you currently have a mature/well-developed data warehouse, I certainly wouldn't advise removing it and starting from scratch. Many companies are starting to implement data lakes in tandem with a data warehouse.
The data warehouse can then operate as usual and you can start filling your data lake with new data. The data lake can then be used for the collection of warehouse data that you archive. This is then available for your users to continue to use.
Over time you can move all your data to your data lake or you may continue using both the warehouse and lake in the same way.
Find out more about our Data and AI solutions, and speak to a data expert.